publications
List of never up-to-date publications.
oficial publication lists
list of publications
2026
-
-
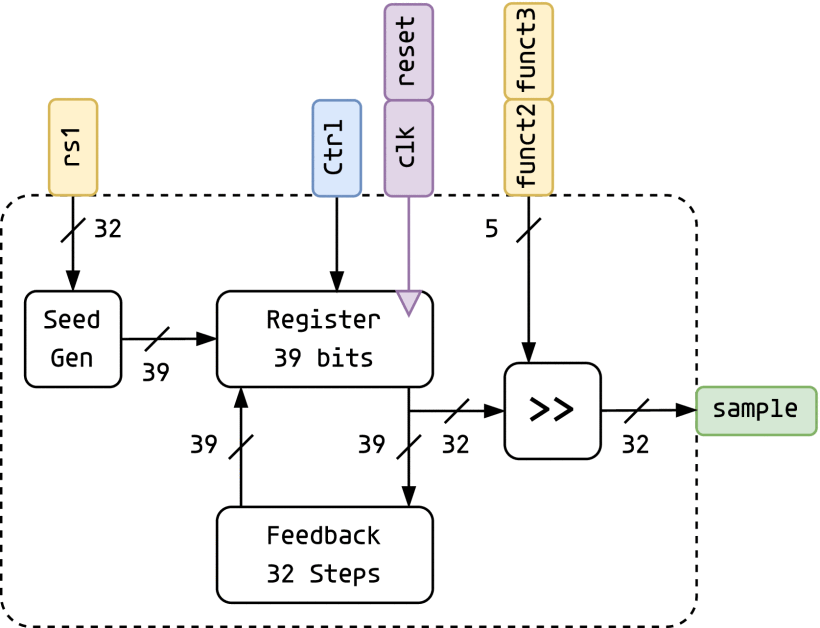 BnnRV: Hardware and Software Optimizations for Weight Sampling in Bayesian Neural Networks on Edge RISC-V CoresIEEE Trans. Circuits Syst. Artif. Intell., 2026
BnnRV: Hardware and Software Optimizations for Weight Sampling in Bayesian Neural Networks on Edge RISC-V CoresIEEE Trans. Circuits Syst. Artif. Intell., 2026
2025
-
 FLAMA: Architecting Floating-Point Atomic Memory Operations for Heterogeneous HPC SystemsIn 28th Euromicro Conference on Digital System Design, DSD 2025, Salerno, Italy, September 10-12, 2025, 2025
FLAMA: Architecting Floating-Point Atomic Memory Operations for Heterogeneous HPC SystemsIn 28th Euromicro Conference on Digital System Design, DSD 2025, Salerno, Italy, September 10-12, 2025, 2025 -
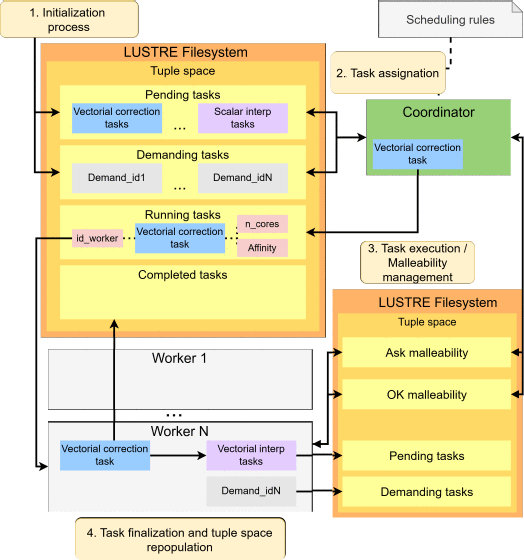 Tuple Spaces for Workflow Scheduling and Core-Level Malleability in HpcIn 32nd IEEE International Conference on High Performance Computing, Data, and Analytics, HiPC 2025, Hyderabad, India, December 17-20, 2025, 2025
Tuple Spaces for Workflow Scheduling and Core-Level Malleability in HpcIn 32nd IEEE International Conference on High Performance Computing, Data, and Analytics, HiPC 2025, Hyderabad, India, December 17-20, 2025, 2025 -
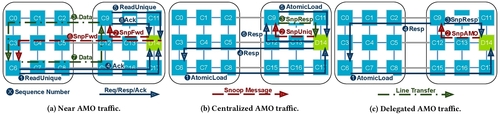 Delegato: Locality-Aware Atomic Memory Operations on ChipletsIn Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, MICRO 2025, Seoul, Republic of Korea, October 18-22, 2025, 2025
Delegato: Locality-Aware Atomic Memory Operations on ChipletsIn Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, MICRO 2025, Seoul, Republic of Korea, October 18-22, 2025, 2025
2024
-
 SpectralWaste Dataset: Multimodal Data for Waste Sorting AutomationIn IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2024, Abu Dhabi, United Arab Emirates, October 14-18, 2024, 2024
SpectralWaste Dataset: Multimodal Data for Waste Sorting AutomationIn IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2024, Abu Dhabi, United Arab Emirates, October 14-18, 2024, 2024
2023
-
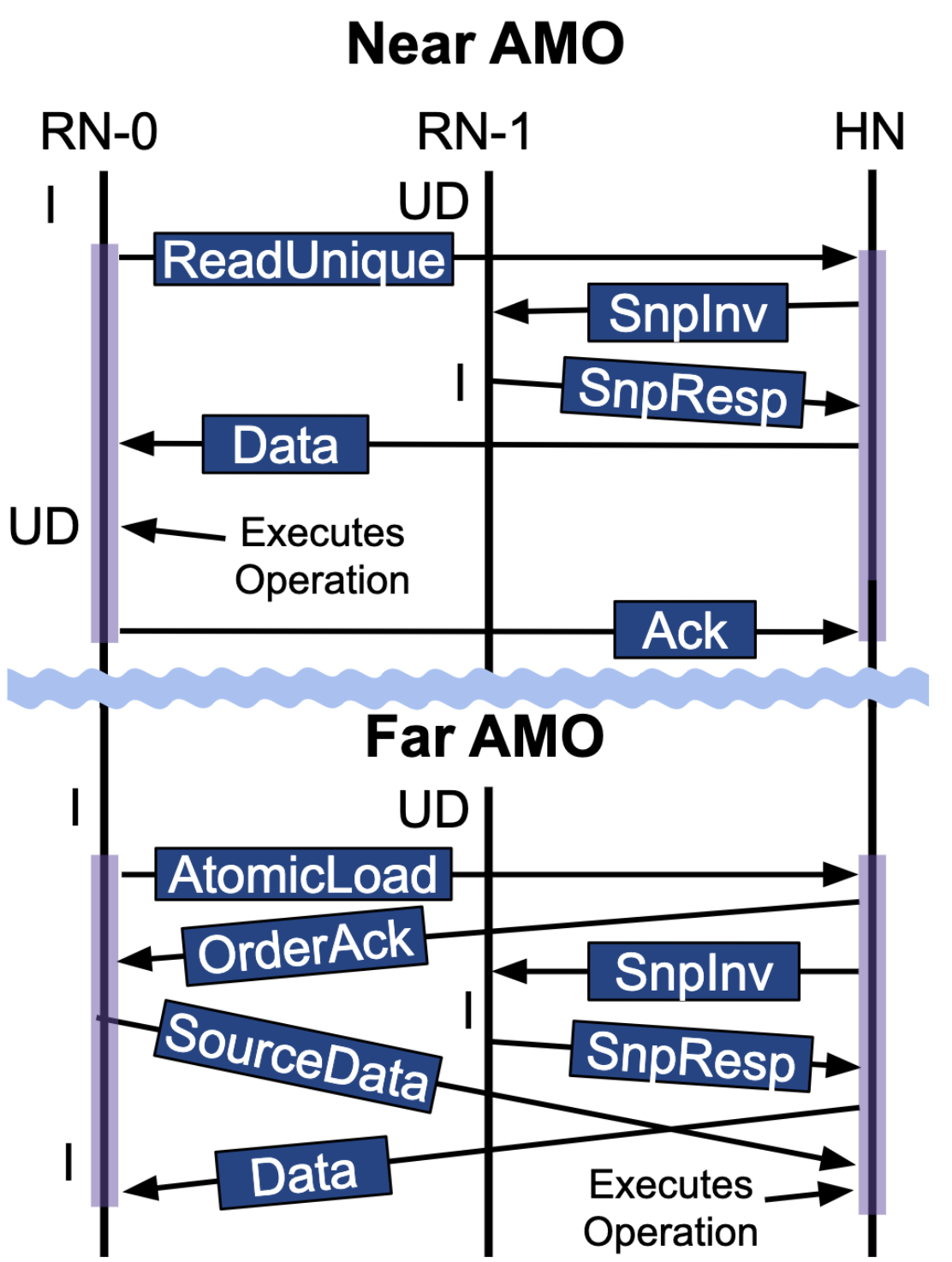 DynAMO: Improving Parallelism Through Dynamic Placement of Atomic Memory OperationsIn Proceedings of the 50th Annual International Symposium on Computer Architecture, ISCA 2023, Orlando, FL, USA, June 17-21, 2023, 2023
DynAMO: Improving Parallelism Through Dynamic Placement of Atomic Memory OperationsIn Proceedings of the 50th Annual International Symposium on Computer Architecture, ISCA 2023, Orlando, FL, USA, June 17-21, 2023, 2023
2022
-
-
Lightweight asynchronous scheduling in heterogeneous reconfigurable systemsJ. Syst. Archit., 2022
-
peRISCVcope: A Tiny Teaching-Oriented RISC-V InterpreterIn 37th Conference on Design of Circuits and Integrated Systems, DCIS 2022, Pamplona, Spain, November 16-18, 2022, 2022
-
Efficient Semantic Segmentation with Hyperspectral ImagesIn ROBOT 2022: Fifth Iberian Robotics Conference - Advances in Robotics, Volume 1, Zaragoza, Spain, 23-25 November 2022, 2022
2021
-
A learning experience toward the understanding of abstraction-level interactions in parallel applicationsJ. Parallel Distributed Comput., 2021
-
Analytical Model for Memory-Centric High Level Synthesis-Generated ApplicationsIEEE Trans. Computers, 2021
-
-
A Cross-Platform OpenVX Library for FPGA AcceleratorsIn 29th Euromicro International Conference on Parallel, Distributed and Network-Based Processing, PDP 2021, Valladolid, Spain, March 10-12, 2021, 2021
-
RRCD: Redirección de Registros Basada en Compresión de Datos para Tolerar FallosPermanentes en una GPUCoRR, 2021
2020
-
DC-Patch: A Microarchitectural Fault Patching Technique for GPU Register FilesIEEE Access, 2020
-
Parallel multiprocessing and scheduling on the heterogeneous Xeon+FPGA platformJ. Supercomput., 2020
-
An Analytical Model of Memory-Bound Applications Compiled with High Level SynthesisIn 28th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, FCCM 2020, Fayetteville, AR, USA, May 3-6, 2020, 2020
-
Analytical Model of Memory-Bound Applications Compiled with High Level SynthesisCoRR, 2020
2019
-
A fault-tolerant last level cache for CMPs operating at ultra-low voltageJ. Parallel Distributed Comput., 2019
-
Exploring heterogeneous scheduling for edge computing with CPU and FPGA MPSoCsJ. Syst. Archit., 2019
-
-
-
-
Correction to: Simultaneous multiprocessing in a software-defined heterogeneous FPGAJ. Supercomput., 2019
-
Exposing Abstraction-Level Interactions with a Parallel Ray TracerIn Proceedings of the Workshop on Computer Architecture Education, WCAE@ISCA 2019, Phoenix, AZ, USA, June 22, 2019, 2019
2018
-
Towards the Inclusion of FPGAs on Commodity Heterogeneous SystemsIn 2018 International Conference on High Performance Computing & Simulation, HPCS 2018, Orleans, France, July 16-20, 2018, 2018
-
Parallelizing Workload Execution in Embedded and High-Performance Heterogeneous SystemsCoRR, 2018
-
AISC: Approximate Instruction Set ComputerCoRR, 2018
2017
-
Abstract Representation of Shared Data for Heterogeneous ComputingIn Languages and Compilers for Parallel Computing - 30th International Workshop, LCPC 2017, College Station, TX, USA, October 11-13, 2017, Revised Selected Papers, 2017
-
Simultaneous Multiprocessing on a FPGA+CPU Heterogeneous System-On-ChipIn Parallel Computing is Everywhere, Proceedings of the International Conference on Parallel Computing, ParCo 2017, 12-15 September 2017, Bologna, Italy, 2017
-
Exploiting Data Compression to Mitigate Aging in GPU Register FilesIn 29th International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD 2017, Campinas, Brazil, October 17-20, 2017, 2017
2016
-
Reactive circuits: Dynamic construction of circuits for reactive traffic in homogeneous CMPsJ. Parallel Distributed Comput., 2016
-
Analysis of network-on-chip topologies for cost-efficient chip multiprocessorsMicroprocess. Microsystems, 2016
-
Concertina: Squeezing in Cache Content to Operate at Near-Threshold VoltageIEEE Trans. Computers, 2016
2015
2014
-
Revisiting LP-NUCA Energy Consumption: Cache Access Policies and Adaptive Block DroppingACM Trans. Archit. Code Optim., 2014
-
Dynamic construction of circuits for reactive traffic in homogeneous CMPsIn Design, Automation & Test in Europe Conference & Exhibition, DATE 2014, Dresden, Germany, March 24-28, 2014, 2014
-
Block Disabling Characterization and Improvements in CMPs Operating at Ultra-low VoltagesIn 26th IEEE International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD 2014, Paris, France, October 22-24, 2014, 2014
2013
-
Shrinking L1 Instruction Caches to Improve Energy-Delay in SMT Embedded ProcessorsIn Architecture of Computing Systems - ARCS 2013 - 26th International Conference, Prague, Czech Republic, February 19-22, 2013. Proceedings, 2013
-
Characterization and cost-efficient selection of NoC topologies for general purpose CMPsIn Proceedings of the 2013 Interconnection Network Architecture: On-Chip, Multi-Chip, IMA-OCMC@HiPEAC 2013, Berlin, Germany, January 23, 2013, 2013
2012
-
LP-NUCA: Networks-in-Cache for High-Performance Low-Power Embedded ProcessorsIEEE Trans. Very Large Scale Integr. Syst., 2012
-
Automatic discovery of performance and energy pitfalls in HTML and CSSIn Proceedings of the 2012 IEEE International Symposium on Workload Characterization, IISWC 2012, La Jolla, CA, USA, November 4-6, 2012, 2012
2009
-
Light NUCA: A proposal for bridging the inter-cache latency gapIn Design, Automation and Test in Europe, DATE 2009, Nice, France, April 20-24, 2009, 2009
-
SigRace: signature-based data race detectionIn 36th International Symposium on Computer Architecture (ISCA 2009), June 20-24, 2009, Austin, TX, USA, 2009
2007
-
A proposal to introduce power and energy notions in computer architecture laboratoriesIn Proceedings of the 2007 Workshop on Computer Architecture Education, WCAE 2007, San Diego, California, USA, Saturday, June 9, 2007, 2007