Towards semantic SLAM using a monocular camera
Abstract
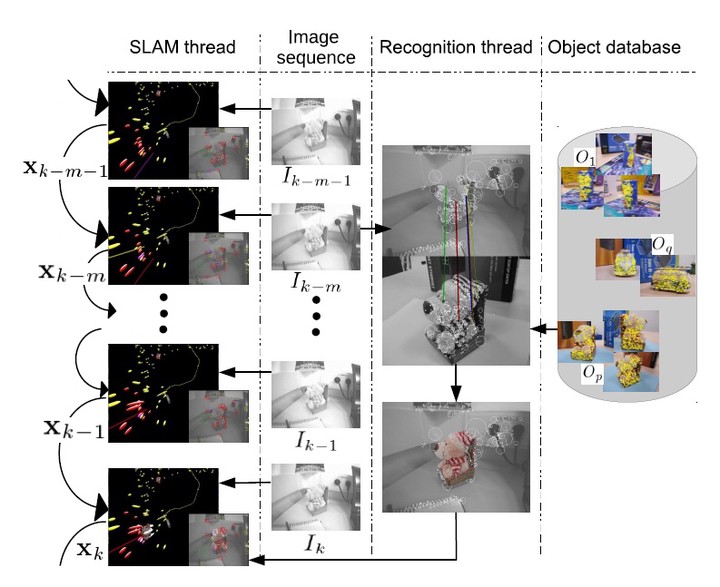
Monocular SLAM systems have been mainly focused on producing geometric maps just composed of points or edges; but without any associated meaning or semantic content. In this paper, we propose a semantic SLAM algorithm that merges in the estimated map traditional meaningless points with known objects. The non-annotated map is built using only the information extracted from a monocular image sequence. The known object models are automatically computed from a sparse set of images gathered by cameras that may be different from the SLAM camera. The models include both visual appearance and tridimensional information. The semantic or annotated part of the map -the objects- are estimated using the information in the image sequence and the precomputed object models. The proposed algorithm runs an EKF monocular SLAM parallel to an object recognition thread. This latest one informs of the presence of an object in the sequence by searching for SURF correspondences and checking afterwards their geometric compatibility. When an object is recognized it is inserted in the SLAM map, being its position measured and hence refined by the SLAM algorithm in subsequent frames. Experimental results show real-time performance for a hand held camera imaging a desktop environment and for a camera mounted in a robot moving in a room-sized scenario.