El programa que se desarrollará en esta práctica genera
sentencias aleatorias en inglés. Esta es una gramática simple
para una pequeña porción de inglés:
Sentencia ^ Nombre_de _frase + Verbo_de
_frase
Nombre_de _frase ^ Artículo + Nombre
Verbo_de _frase ^ Verbo + Nombre_de _frase
Artículo ^the, a,
Nombre ^ man, ball, woman, table
Verbo ^ hit, took, saw, liked
Para ser técnicos, esta descripción se llama gramática
de estructura-de-frase de contexto-libre, y el paradigma subyacente
se llama sintaxis generativa. La idea es que en cualquier sitio
donde se requiere una sentencia, podemos generarla con el nombre
de la frase seguido por el verbo de la frase. Donde se requiera el nombre
de la frase podemos poner en su lugar un artículo seguido
de un nombre. Donde se especifique un artículo, podemos
poner "the", "a", o cualquier otro artículo. El formalismo
es de contexto-libre porque las reglas se aplican en cualquier sitio
independientemente de las palabras que le rodean, y la aproximación
es generativa porque las reglas en conjunto definen el conjunto
completo de sentencias del lenguaje (y por contraste el conjunto de no-sentencias
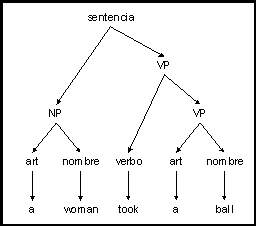
también). A continuación mostramos la derivación de
una sentencia simple utilizando las anteriores reglas:
Para obtener una Sentencia, añadimos un Nombre-de-frase y
un Verbo-de-frase
Para obtener un Nombre-de-frase, añadir un Artículo
y un Nombre
Elegir the para el Artículo
Elegir man para el Nombre
El Nombre-de-frase resultante es the man
Para obtener un Verbo-de-frase, añadir un Verbo y
un Nombre-de-frase
Elegir hit para el Verbo
Para obtener un Nombre-de-frase, añadir
un Artículo y un Nombre
Elegir the para el Artículo
Elegir ball para el Nombre
El Nombre-de-frase resultante es the ball
El Verbo-de-frase resultante es hit the ball
La Sentencia resultante es the man hit the ball
La aproximación más elemental es representar cada regla
gramatical por una función Lisp separada:
(defun Sentencia ()
(append (Nombre-frase) (Verbo-frase)))
(defun Nombre-frase () (append
(Articulo) (Nombre)))
(defun Verbo-frase ()
(append (Verbo) (Nombre-frase)))
(defun Articulo ()
(uno-de '(the a)))
(defun Nombre ()
(uno-de '(man ball woman table)))
(defun Verbo ()
(uno-de '(hit took saw liked)))
Algunas de estas definiciones utilizan la función
uno-de que recibe como argumento posibles valores y devuelve uno elegido
aleatoriamente metido en una lista. De esta forma se puede aplicar append
a todas las categorías.
(defun uno-de (conjunto)
"Elige un elemento del conjunto
y lo mete en una lista."
(list (random-elt conjunto)))
(defun random-elt (posibilidades)
"Elige aleatoriamente un
elemento de una lista."
(elt posibilidades(random
(length posibilidades))))
Notar que la función elt no
es más que la nth (enésimo elemento) con los parámetros
intercambiados: (elt lista n) y (nth n lista).
Ahora podemos hacer una prueba generando unas pocas
sentencias y partes de sentencia:
> (sentencia) ->(A BALL
LIKED A MAN)
> (sentencia) ->(A MAN
SAW A WOMAN)
> (sentencia) ->(THE
BALL HIT A MAN)
> (sentencia) ->(A BALL
HIT A WOMAN)
> (sentencia) ->(A WOMAN
TOOK A TABLE)
> (sentencia) ->(THE
BALL HIT A TABLE)
> (sentencia) ->(THE
BALL SAW A TABLE)
> (sentencia) ->(THE MAN TOOK
A TABLE)
> (sentencia) ->(THE
BALL SAW THE TABLE)
> (sentencia) ->(THE
BALL LIKED A TABLE)
> (sentencia) ->(THE
WOMAN SAW THE TABLE)
> (nombre-frase) ->(A TABLE)
> (verbo-frase) ->(HIT A WOMAN)
> (nombre-frase) ->(THE WOMAN)
> (verbo-frase) ->(TOOK THE
TABLE)
> (verbo-frase) ->(SAW A BALL)
> (verbo-frase) ->(HIT A BALL)
>
> (trace nombre-frase verbo-frase
articulo nombre verbo)
(NOMBRE-FRASE VERBO-FRASE ARTICULO
NOMBRE VERBO)
>
> (sentencia)
; 1> NOMBRE-FRASE called with no
args
; 2> ARTICULO called with no args
; 2< ARTICULO returns value:
;
(THE)
; 3> NOMBRE called with no args
; 3< NOMBRE returns value:
;
(BALL)
; 1< NOMBRE-FRASE returns value:
;
(THE BALL)
; 4> VERBO-FRASE called with no
args
; 5> VERBO called with no args
; 5< VERBO returns value:
;
(TOOK)
; 6> NOMBRE-FRASE called with no
args
; 7> ARTICULO called with no args
; 7< ARTICULO returns value:
;
(A)
; 8> NOMBRE called with no args
; 8< NOMBRE returns value:
;
(MAN)
; 6< NOMBRE-FRASE returns value:
;
(A MAN)
; 4< VERBO-FRASE returns value:
;
(TOOK A MAN)
(THE BALL TOOK A MAN)
>
Estas funciones trabajan bien y la traza tiene el
estilo de la que derivamos anteriormente pero las definiciones de funciones
son más duras de leer que las reglas gramaticales originales. Este
problema surgirá con más intensidad al considerar reglas
más complejas. Supongamos que queremos permitir que los nombres
de frases puedan ser modificados por un número indefinido de adjetivos
y un número indefinido de frases preposicionales. En notación
gramatical, podemos considerar las siguientes nuevas reglas:
Nombre_de _frase ^ Artículo
+ Adj* + Nombre + PP*
Nombre_de _frase ^ Artículo
+ Adj* + Nombre + PP*
Adj* ^ 0, Adj + Adj*
PP* ^ 0, PP + PP*
PP ^ Prep + Nombre-frase
Adj ^ big, little, blue, green,
Prep ^ to, in, by, with,
En esta notación ( ) indica la posibilidad
de ningún elemento, una coma indica una elección de entre
varias alternativas, los nombres terminados en un asterisco denotan cero
o más repeticiones del nombre (esto es, PP* denota cero o más
repeticiones de PP).
El problema aquí es que las reglas para Adj*
y PP* contienen elecciones que deben programarse con algún mecanismo
condicional. Por ejemplo:
(defun Adj* ()
(if (= (random 2) 0)
nil
(append
(Adj) (Adj*))))
(defun PP* ()
(if (random-elt '(t nil))
(append
(PP) (PP*))
nil))
(defun Nombre-frase () (append
(Articulo) (Adj*) (Nombre) (PP*)))
(defun PP () (append (Prep)
(Nombre-frase)))
(defun Adj () (uno-de '(big
little blue green adiabatic)))
(defun Prep () (uno-de '(to
in by with on)))
Para definir la gramática hemos empezado con
funciones simples pero se están convirtiendo cada vez más
complejas. Para comprenderlas, necesitamos conocer muchas convenciones
de Lisp (defun, case, if, quote,
reglas de evaluación,
) cuando idealmente la implementación
de unas reglas gramaticales deberían utilizar sólo convenciones
linguísticas. Si quisiéramos desarrollar una gramática
más grande, el problema podría ser peor porque las reglas
dependerían cada vez más de Lisp.
2.2.3 Una solución basada en reglas
Una implementación alternativa de este programa
podría concentrarse en facilitar la escritura de las reglas gramaticales
y dejar para más adelante la preocupación sobre como pueden
ser procesadas. Hechemos un vistazo otra vez a las reglas gramaticales
originales:
Sentencia ^ Nombre_de _frase + Verbo_de
_frase
Nombre_de _frase ^ Artículo + Nombre
Verbo_de _frase ^ Verbo + Nombre_de _frase
Artículo ^ the, a,
Nombre^ man, ball, woman, table
Verbo ^ hit, took, saw, liked
Cada regla consiste en una flecha con un símbolo
en la parte izquierda y algo en la parte derecha. La complicación
es que hay dos posibilidades para la parte derecha: una lista concatenada
de símbolos, como "Nombre_de _frase ^ Artículo
+ Nombre", o una lista de palabras alternativas como en "Nombre ^
man, ball, woman, table
". Podríamos representar la lista concatenada
de símbolos como una lista p.e. "(Artículo Nombre)",
mientras que las palabras alternativas podrían ser representados
directamente como símbolos "man, ball, woman, table". Según
este estilo de representación las reglas quedarían de la
siguiente forma:
(defparameter *gramatica-simple*
'((Sentencia -> (Nombre-frase
Verbo-frase))
(Nombre-frase
-> (Articulo Nombre))
(Verbo-frase
-> (Verbo Nombre-frase))
(Articulo ->
the a)
(Nombre -> man
ball woman table)
(Verbo -> hit
took saw liked))
"Gramatica para un subconjunto
trivial de Ingles.")
(defvar *gramatica* *gramatica-simple*
"Gramatica utilizada para
generar. Inicialmente esta es la
*gramatica-simple*, pero
puede conmutarse por otras gramaticas.")
Notar que la versión de Lisp basada en reglas
imita muy fielmente la versión original (se ha incluido incluso
el símbolo ->
sólo con propósitos decorativos pero sin ningún papel
real).
Las formas especiales defvar
y defparameter introducen
variables especiales y se les ligan un valor. La diferencia es que el valor
ligado a una variable como *gramatica*
puede ser cambiado durante la ejecución del programa. Mientras que
un parámetro como *gramatica-simple*
permanecerá constante.
Una vez se han definido la lista de reglas gramaticales,
pueden ser utilizadas para encontrar las posibles sustituciones de una
categoría. La función assoc está diseñada precisamente
para este tipo de tarea. Tiene dos argumentos, una "clave" y una lista
de listas, y devuelve el primer elemento de la lista de listas que comienza
por esa clave. Si no hay ninguno, devuelve nil. Aquí hay un ejemplo:
> (assoc 'Nombre *gramatica*)
(NOMBRE -> MAN BALL WOMAN TABLE)
Aunque las reglas resultan bastante simples implementadas
como reglas, es una buena idea imponer un nivel de abstracción definiendo
funciones que operen con las reglas. Necesitaremos tres funciones:
(defun regla-pir (regla)
"Parte izquierda de una regla."
(first regla))
(defun regla-pdr (regla)
"Parte derecha de una regla."
(rest (rest regla)))
(defun sustituciones (categoria)
"Devuelve una lista con todas
las posibles sustituciones de una
categoria."
(regla-pdr (assoc categoria
*gramatica*)))
Definiendo estas funciones facilitaremos hacer cambios
en la representación de las reglas y la lectura de los programas
que las usan.
Ahora estamos listos para abordar el problema principal:
definir una función (que llamaremos genera)
que ejecutará las sentencias (o nombres de frase o cualquier otra
categoría). Esta función tendrá que abordar tres casos:
-
En el caso más simple, le llegará un símbolo
que tiene un conjunto de reglas de sustitución ligadas a el. Se
elige una aleatoriamente y se genera de él.
-
Si el símbolo no tiene reglas de sustitución,
debe ser un símbolo terminal (una palabra más que una categoría
gramatical). Se deja como está (en realidad se devuelve metida en
una lista porque se quiere que todos los resultados sean listas de palabras).
-
En algunos casos, cuando el símbolo tiene sustituciones,
se cogerá una que es una lista de símbolos, y se tratará
de generar de ahí. Así, genera
debe aceptar también una lista como entrada, en cuyo caso debe generar
cada elemento de la lista y añadirlos todos juntos.
(defun genera (frase)
"Genera una sentencia o frase
aleatoria."
(cond ((listp frase)
(mapcan #'genera frase))
((sustituciones frase) ;devuelve p.e. ((nombre verbo))
(genera (random-elt (sustituciones frase))))
(t (list frase))))
Esta es una función corta pero densa de información.
Este estilo de programación se denomina programación dirigida
por los datos, debido a que los datos (la lista de sustituciones asociada
con cada categoría) dirige lo que el programa debe hacer a continuación.
Esto es un estilo natural y fácil-de-utilizar en Lisp y conduce
a programas concisos y extensibles pues siempre es posible añadir
una nueva pieza de datos con una nueva asociación sin tener que
modificar el programa original.
Aquí están algunos ejemplos del uso
de genera:
> (genera 'sentencia)
->(LEE TOOK PAT TO THOSE IN THE BALL ...)
> (genera 'sentencia) ->(ROBIN
HIT SHE)
> (genera 'sentencia) ->(IT
TOOK A BIG GREEN TABLE)
> (genera 'sentencia) ->(LEE
HIT KIM)
> (genera 'sentencia) ->(A
MAN LIKED TERRY BY A BLUE MAN)
> (genera 'Nombre-frase) ->(HE)
> (genera 'Nombre-frase) ->(ROBIN)
> (genera 'Nombre-frase) ->(A
WOMAN)
> (genera 'Verbo-frase) ->(TOOK
THE BIG MAN BY IT WITH HE)
> (genera 'Verbo-frase) ->(LIKED
LEE)
> (genera 'Verbo-frase) ->(TOOK
THE WOMAN WITH TERRY WITH THE MAN
...)
> (genera 'Verbo-frase) ->(LIKED
LEE)
> (genera 'Verbo-frase) ->(LIKED
ROBIN BY A TABLE IN THE MAN)
>
Hay otras muchas formas posibles
de escribir genera. La siguiente versión utiliza if en lugar de
cond:
(defun genera (frase)
"Genera una sentencia o frase
aleatoria."
(if (listp frase)
(mapcan
#'genera frase)
(let ((posibilidades
(sustituciones frase)))
(if (null posibilidades)
(list frase)
(genera (random-elt (sustituciones frase)))))))
Esta versión utiliza la forma especial let,
que introduce una nueva variable (en este caso, posibilidades)
y liga un valor a dicha variable. En este caso, la introducción
de la variable nos evita llamar dos veces a la función sustituciones,
como se hizo en la anterior versión.